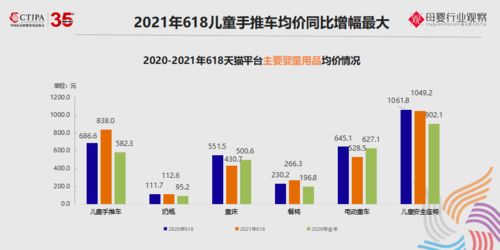
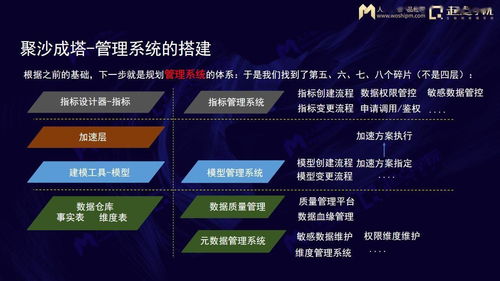
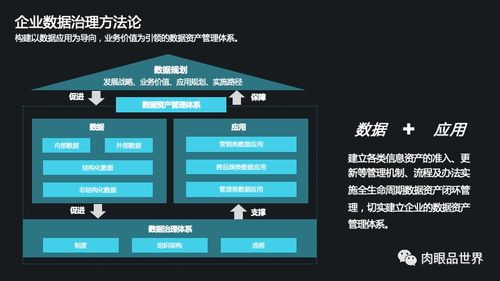
隨著全球對環保的重視以及“無廢城市”等政策的推進,垃圾分揀行業被廣泛視為下一個千億級市場。據估算,僅中國市場的潛在規模就可能突破2000億元。這一數字背后,不僅隱藏著傳統垃圾分類與回收產業的轉型升級,更凸顯了技術驅動下數據處理服務所扮演的關鍵角色。
一方面,垃圾分揀已不再是簡單的人工分類或基礎機械篩選。從智能識別攝像頭、傳感器網絡到機器人分揀臂,海量數據在分揀過程中實時產生。這些數據涵蓋了垃圾成分、數量、流向乃至用戶投放習慣等多個維度。若缺乏高效的數據處理服務,這些信息只能是沉睡的“數據垃圾”,無法轉化為優化運營、提升回收率的價值資產。
另一方面,現實中的垃圾分揀行業仍面臨諸多挑戰:分類準確率不足、運營成本高企、資源化利用路徑不暢等。要突破這些瓶頸,恰恰需要更“狂野”的想象——即通過數據建模、人工智能算法和物聯網技術,構建覆蓋全鏈條的智能分揀與管理系統。例如,基于歷史數據訓練AI模型,可實現垃圾種類的精準識別與自動分揀;通過數據分析預測垃圾產生高峰,能動態調整清運路線與資源分配;甚至借助區塊鏈技術追溯垃圾流向,提升回收材料的可信度與附加值。
因此,數據處理服務已成為垃圾分揀行業不可或缺的基礎設施。它不僅能夠提升分揀效率、降低人力成本,更能通過數據洞察驅動循環經濟模式的創新——比如將分揀數據與再生產品設計、市場需求對接,實現資源的最大化利用。
垃圾分揀行業的真正爆發,必然建立在數據智能的深度融合之上。2000億風口并非終點,而是一個起點。唯有以數據處理服務為引擎,持續推動技術迭代與應用場景拓展,才能讓垃圾分類從“政策要求”走向“經濟引擎”,真正實現環境效益與商業價值的雙贏。